یکی از سوالاتی که برای بعضی از دوستان پیش می آید این است که آیا ترتیب تعریف ستون های یک جدول تاثیری بر عملکرد کوئری ها دارد؟
برای پاسخ به این سوال، به نحوه ذخیره سازی سطرهای جداول در یک block توجه فرمایید که به شکل زیر است:
Dn |
Ln |
… |
D3 |
L3 |
D2 |
L2 |
D1 |
L1 |
H |
H: Header
Ln: Length of Column n
Dn: Data of Column n
این نکات را در نظر داشته باشید:
- خواندن block به شکل سریال است، پس برای خوانده شدن اطلاعات ستون دوم، به ناچار ستون اول هم خوانده می شود و ...
- برای مقادیر null چیزی ذخیره نمی شود.
پس با توجه به موارد بالا، در طراحی جدول این نکات را در نظر داشته باشید:
- ستون هایی را که خیلی استفاده می شوند را در ابتدا تعریف کنید. (به علت سریالی خوانده شدن block). تاثیر این نکته وقتی بیشتر مشخص می شود که جدولی داریم با ستون های زیاد و ما فقط چند ستون آن را به تناوب نیاز داریم.
- تنها ستون هایی را در دستور select بیاورید که واقعاً مورد نیاز هستند.
- ستون های یک جدول که می توانند مقادیر null داشته باشند را در انتهای ستون های جدول تعریف کنید.
حالا نگاهی هم به هزینه اجرای دستورات می اندازیم. برای این کار جدول test_cost_tbl را با پنج ستون می سازیم:
drop table test_cost_tbl purge;
CREATE TABLE test_cost_tbl(
col_1 NUMBER,
col_2 NUMBER,
col_3 NUMBER,
col_4 NUMBER,
col_5 NUMBER);
سپس یک سطر در این جدول insert و آمار جدول را نیز بروز رسانی میکنیم:
INSERT INTO test_cost_tbl VALUES (1, 2, 3, 4, 5); commit; begin dbms_stats.gather_table_stats(user,'test_cost_tbl'); end;
برای خواندن هر کدام از ستون های جدول به صورت مجزا و تهیه Plan اجرای آنها از دستورات زیر استفاده می کنیم:
EXPLAIN PLAN SET STATEMENT_ID 'col_1' FOR SELECT col_1 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_2' FOR SELECT col_2 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_3' FOR SELECT col_3 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_4' FOR SELECT col_4 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_5' FOR SELECT col_5 FROM test_cost_tbl;
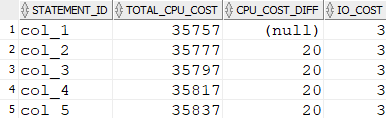
با بررسی مقادیر ثبت شده در جدول plan_table می توانیم مشاهده کنیم که هزینه CPU خواندن از ستون ها با هم متفاوت است (20 عدد به ازا هر ستون به هزینه CPU اضافه می شود) اما هزینه I/O آنها ثابت مانده است. علت ثابت ماندن هزینه I/O احتمالاً این است که کل رکورد در یک بلاک ذخیره شده اند و برای خواندن آن نیاز به I/O اضافی نیست.
SELECT statement_id, cpu_cost as total_cpu_cost,cpu_cost-lag(cpu_cost) OVER (ORDER BY statement_id) AS cpu_cost_diff, io_cost FROM plan_table WHERE id = 0 ORDER BY statement_id;
خروجی دستور بالا به شکل تصویر زیر قابل مشاهده است:
پی نوشت:
این مطلب و مثال را چند سال پیش از یک وبلاگ خواندم و مستند کردم. متاسفانه آن وبلاگ را پیدا نکردم تا ارجاع بدهم که در این مورد عذرخواهی میکنم.
موفق باشید